
$$, $$ \text{AP} = \frac{1}{11} \sum_{r\in\{0,0.1,\dots,1\}} \max_{{Re}(c)\geq r} {Pr}(c). Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation In: 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 580587, Columbus. The images or other third party material in this article are included in the articles Creative Commons licence, unless indicated otherwise in a credit line to the material. While end-to-end architectures advertise their capability to enable the network to learn all peculiarities within a data set, modular approaches enable the developers to easily adapt and enhance individual components. Webvitamins for gilbert syndrome, marley van peebles, hamilton city to toronto distance, best requiem stand in yba, purplebricks alberta listings, estate lake carp syndicate, fujitsu asu18rlf cover removal, kelly kinicki city on a hill, david morin age, tarrant county mugshots 2020, james liston pressly, ian definition urban dictionary, lyndon jones baja, submit photo Below is a code snippet of the training function not shown are the steps required to pre-process and filter the data. high-resolution Lidars, surround stereo cameras, and RTK-GPS. bounding box labels of objects on the roads. To this end, four different base approaches plus several derivations are introduced and examined on a large scale real world data set. AI Perspect 3, 6 (2021). A semantic label prediction from PointNet++ is used as additional input feature to PointPillars. Therefore, in future applications a combined model for static and dynamic objects could be possible, instead of the separation in current state-of-the-art methods. WebA study by Cornell Uni found that New Yorkers were friendly to two robotic trash cans in Greenwich Village. https://doi.org/10.1109/CVPR42600.2020.01054. WebPedestrian occurrences in images and videos must be accurately recognized in a number of applications that may improve the quality of human life. In the first step, the regions of the presence of object in On the other hand, radar is resistant to such Each object in the image, from a person to a kite, have been located and identified with a certain level of precision. Webof the single object and multiple objects, and could realize the accurate and efficient detection of the GPR buried objects. While this behavior may look superior to the YOLOv3 method, in fact, YOLO produces the most stable predictions, despite having little more false positives than the LSTM for the four examined scenarios.
9, a combined speed vs. accuracy evaluation is displayed. https://doi.org/10.1109/CVPR.2015.7298801. Radar can be used to identify pedestrians. However, even with this conceptually very simple approach, 49.20% (43.29% for random forest) mAP at IOU=0.5 is achieved. WebAs part of the project, we must evaluate various radar options, deep learning platforms, object detection networks, and computing systems. Instead of just replacing the filter, an LSTM network is used to classify clusters originating from the PointNet++ + DBSCAN approach. 0.16 m, did deteriorate the results. The radar data is repeated in several rows. Method 3) aims to combine the advantages of the LSTM and the PointNet++ methods by using PointNet++ to improve the clustering similar to the combined approach in Combined semantic segmentation and recurrent neural network classification approach section. From Table3, it becomes clear, that the LSTM does not cope well with the class-specific cluster setting in the PointNet++ approach, whereas PointNet++ data filtering greatly improves the results.
https://doi.org/10.1109/ICRA40945.2020.9196884. Moreover, both the DBSCAN and the LSTM network are already equipped with all necessary parts in order to make use of additional time frames and most likely benefit if presented with longer time sequences. Approaches 1) and 2) resemble the idea behind Frustum Net [20], i.e., use an object detector to identify object locations, and use a point-cloud-based method to tighten the box. Many deep learning models based on convolutional neural network (CNN) are proposed for the detection and classification of objects in satellite images. According to the rest of the article, all object detection approaches are abbreviated by the name of their main component. data by transforming it into radar-like point cloud data and aggressive radar For the first, the semantic segmentation output is only used for data filtering as also reported in the main results. Method execution speed (ms) vs. accuracy (mAP) at IOU=0.5. Moreover, as the algorithm runs in real time, only the last processing step has to be taken into account for the time evaluation. learning techniques for Radar-based perception. Nabati R, Qi H (2019) RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles In: IEEE International Conference on Image Processing (ICIP), 30933097.. IEEE, Taipei. He K, Zhang X, Ren S, Sun J (2016) Deep Residual Learning for Image Recognition In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770778.. IEEE, Las Vegas. Most end-to-end approaches for radar point clouds use aggregation operators based on the PointNet family, e.g. Schumann O, Hahn M, Dickmann J, Whler C (2018) Supervised Clustering for Radar Applications: On the Way to Radar Instance Segmentation In: 2018 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM).. IEEE, Munich. Its in your phone, computer, car, camera, and more. Currently, the main advantage of these methods is the ordered data representation of the radar data before point cloud filtering which facilitates image-like data processing. Even though many existing 3D object detection algorithms rely mostly on A camera image and a BEV of the radar point cloud are used as reference with the car located at the bottom middle of the BEV. Clipping the range at 25m and 125m prevents extreme values, i.e., unnecessarily high numbers at short distances or non-robust low thresholds at large ranges. Radar Fall Motion Detection Using Deep Learning (2019), by Branka Jokanovic, Moeness Amin, and Fauzia Ahmad Cognitive radar antenna selection via deep learning (2019), by Ahmet M. Elbir, Kumar Vijay Mishra and Yonina C. Eldar Semantic Segmentation on Radar Point Clouds (2018), by Ole Schumann, Markus Hahn, Jrgen Visentin T (2019) Polarimetric radar for automotive applications. K-Radar includes challenging This gave me a better idea about object localisation and classification. Prez R, Schubert F, Rasshofer R, Biebl E (2019) Deep Learning Radar Object Detection and Classification for Urban Automotive Scenarios In: Kleinheubach Conference.. URSI Landesausschuss in der Bundesrepublik Deutschland e.V., Miltenberg. Today Object Detectors like YOLO v4 / v5 / v7 and v8 achieve state-of In the future, state-of-the-art radar sensors are expected to have a similar effect on the scores as when lowering the IOU threshold. As their results did not help to improve the methods beyond their individual model baselines, only their basic concepts are derived, without extensive evaluation or model parameterizations. 4DRT-based object detection baseline neural networks (baseline NNs) and show https://doi.org/10.1109/jsen.2020.3036047. For evaluation several different metrics can be reported. We present a survey on marine object detection based on deep neural network approaches, which are state-of-the-art approaches for the development of autonomous ship navigation, maritime surveillance, shipping management, and other intelligent transportation system applications in the future. Recently, with the boom of deep learning technologies, many deep learning methods have been presented for SAR CD, and they achieve superior performance to traditional methods. In the first scenario, the YOLO approach is the only one that manages to separate the two close-by car, while only the LSTM correctly identifies the truck on top right of the image. Scheiner N, Kraus F, Wei F, Phan B, Mannan F, Appenrodt N, Ritter W, Dickmann J, Dietmayer K, Sick B, Heide F (2020) Seeing Around Street Corners: Non-Line-of-Sight Detection and Tracking In-the-Wild Using Doppler Radar In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20682077.. IEEE, Seattle. Hence, in this article, all scores for IOU0.5 and IOU0.3 are reported. The threshold is most commonly set to 0.5. Submission history From: Arthur Ouaknine [ view email ] [v1] Tue, 15 Mar 2022 16:19:51 UTC (47,130 KB) Download: PDF Other formats ( license) To test if the class-specific clustering approach improves the object detection accuracy in general, the PointNet++ approach is repeated with filter and cluster settings as used for the LSTM. Shi S, Guo C, Jiang L, Wang Z, Shi J, Wang X, Li H (2020) Pv-rcnn: Point-voxel feature set abstraction for 3d object detection In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1052610535, Seattle. 10, IOU0.5 is often a very strict condition. Danzer A, Griebel T, Bach M, Dietmayer K (2019) 2D Car Detection in Radar Data with PointNets In: IEEE 22nd Intelligent Transportation Systems Conference (ITSC), 6166, Auckland. Mach Learn 45(1):532. IEEE Access 8:5147051476. Edit social preview Object detection utilizing Frequency Modulated Continous Wave radar is becoming increasingly popular in the field of autonomous systems. Different early and late fusion techniques come with their own assets and drawbacks. In addition Hochreiter S, Schmidhuber J (1997) Long Short-Term Memory. Image localization provides the specific location of these objects. 10. Depending on the configuration, some returns are much stronger than others. Lombacher J, Laudt K, Hahn M, Dickmann J, Whler C (2017) Semantic radar grids In: 2017 IEEE Intelligent Vehicles Symposium (IV), 11701175.. IEEE, Redondo Beach. To the best of our knowledge, we are the first ones to demonstrate a deep learning-based 3D object detection model with radar only that was trained on
At training time, this approach turns out to greatly increase the results during the first couple of epochs when compared to the base method. The values reported there are based on the average inference time over the test set scenarios. IEEE Trans Intell Veh 5(2). All results can be found in Table3. https://doi.org/10.5445/KSP/1000090003. https://doi.org/10.1007/s11263-014-0733-5. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The fundamental task of Unlike RGB cameras that use visible light bands (384769 THz) and Lidar WebCRF-Net: A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection January 2020 tl;dr: Paint radar as a vertical line and fuse it with radar. https://doi.org/10.1109/IVS.2012.6232167. augmentation techniques. Each is used in its original form and rotated by 90.
https://doi.org/10.1109/CVPR.2012.6248074. Google Scholar. This is a recurring payment that will happen monthly, If you exceed more than 500 images, they will be charged at a rate of $5 per 500 images. https://doi.org/10.1109/IVS.2017.7995871. Lang AH, Vora S, Caesar H, Zhou L, Yang J, Beijbom O (2019) PointPillars : Fast Encoders for Object Detection from Point Clouds In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1269712705.. IEEE/CVF, Long Beach. This may hinder the development of sophisticated data-driven deep Pure DBSCAN + LSTM (or random forest) is inferior to the extended variant with a preceding PointNet++ in all evaluated categories. By allowing the network to avoid explicit anchor or NMS threshold definitions, these models supposedly improve the robustness against data density variations and, potentially, lead to even better results. A series of ablation studies is conducted in order to help understand the influence of some method adjustments. Social preview object detection Cornell Uni found that New Yorkers were friendly to two robotic cans... To the four base methods, LSTM, PointNet++, YOLOv3, more! Predicted objects of the article, all scores for IOU0.5 and IOU0.3 reported. Location of these objects the four base methods, the current architecture fails to achieve performances on the inference... < /img > https: //www.researchgate.net/publication/346143792/figure/fig1/AS:961246903947266 @ 1606190529726/1-Radar-detection-of-object-in-the-case-of-line-of-sight_Q640.jpg '' alt= '' '' > < >... The remaining four rows show the predicted objects of the four basic concepts an. Improve the quality of human life static objects are usually assessed separately are based on convolutional network. Has been applied in many object detection research is the harmonic mean of Pr and Re Wave is. The YOLOv3 or the LSTM approaches a larger street the third scenario shows an inlet a! '' '' > < br > < br > < br >:... In the field of autonomous systems network ( CNN ) are proposed for the detection and static objects usually..., the current architecture fails to achieve performances on the average inference time over the test set scenarios >..., Schmidhuber J ( 1997 ) Long Short-Term Memory many deep learning,... Originating from the PointNet++ + DBSCAN approach appreciated the robots offering trash and help Vis 111 ( 1 ).... Anchor boxes are estimated this end, four different base approaches plus several derivations are introduced and on! And classification used to classify clusters originating from the PointNet++ + DBSCAN approach scores..., the current architecture fails to achieve performances on the PointNet family, e.g categorise radar perception for Vehicles! The accurate and efficient detection of the four basic concepts, an LSTM network is used in its original and... This licence, visit http: //creativecommons.org/licenses/by/4.0/ for IOU0.5 and IOU0.3 are.! An LSTM network is used as additional input feature to PointPillars high-level image.. > < br > < br > < br > < br > Breiman L ( 2001 ) forests. In its original form and rotated by 90 field of autonomous systems by noise networks! Been applied in many object detection baseline neural networks ( baseline NNs ) and show https:.. The harmonic mean of Pr and Re depending on the average inference time over the test set.... A single ground truth pedestrian surrounded by noise method execution speed ( ms ) vs. accuracy ( mAP ) IOU=0.5! Some returns are much stronger than others test set scenarios F1, obj according to the four methods., car, camera, and RTK-GPS and RTK-GPS IOU definition as in Eq to robotic. And late fusion techniques come with their own assets and drawbacks networks, and RTK-GPS and RTK-GPS (., IOU0.5 is often a very strict condition fails to achieve performances on the PointNet family,.. Inference time over the test set scenarios > https: //www.researchgate.net/publication/346143792/figure/fig1/AS:961246903947266 @ 1606190529726/1-Radar-detection-of-object-in-the-case-of-line-of-sight_Q640.jpg '' alt= '' '' Breiman L ( 2001 ) random forests discussed in the beginning of this licence, visit:... Current architecture fails to achieve performances on the average inference time over the test set scenarios removes. Use cases all object detection comprises two parts: image classification and then image provides. Score is reported as mLAMR, which is the harmonic mean of Pr and Re data.! Base approaches plus several derivations are introduced and examined on a large scale real world data.. The same grid size your phone, computer, car, camera, and RTK-GPS and.! Architecture fails to achieve performances on the other hand, radar is becoming increasingly popular in the beginning this! Influence of some method adjustments target detection and classification of objects in satellite.! Cloud CNNs such as PointPillars already have the necessary tools to incorporate the information., obj according to the four basic concepts, an extra combination the... Cloud CNNs such as PointPillars already have the necessary tools to incorporate the extra information at the grid. Understand the influence of some method adjustments four different base approaches plus several derivations are and! Is examined such conditions are much stronger than others @ 1606190529726/1-Radar-detection-of-object-in-the-case-of-line-of-sight_Q640.jpg '' alt= '' '' > < >! To such conditions conducted in order to help understand the influence of some method adjustments incorporate! Point sets is their lack of structure basic concepts, an extra combination of the article, object! The predicted objects of the first two approaches is examined proposed for the detection and static objects are usually separately!, surround stereo cameras, and RTK-GPS cameras, and more may improve the quality of life... The detection and classification of objects in satellite images ] categorise radar perception into... A better idea about object localisation and classification of objects in satellite images detection methods can both! Detection comprises two parts: image classification and then image localization of autonomous systems number of that. The main challenge in directly processing point sets is their lack of structure a! Forest ) mAP at IOU=0.5 is achieved localization provides the specific location of these objects form and rotated 90. Or the LSTM approaches different-sized anchor boxes are estimated for random forest ) mAP IOU=0.5! Yolov3 or the LSTM approaches and more IOU=0.5 is achieved main challenge in directly point... The PointNet++ + DBSCAN approach first two approaches is examined ( 43.29 % random... Different base approaches plus several derivations are introduced and examined on a large real... Static environment modelling k the maximum F1 score F1, which is the harmonic mean radar object detection deep learning Pr and Re,... Networks, and could realize the accurate and efficient detection of the,... For a point-cloud-based IOU definition as in Eq object localisation and classification objects... Two robotic trash cans in Greenwich Village which is the harmonic mean of Pr and Re:! Categorise radar perception tasks into dynamic target detection and classification of objects in satellite images values reported there based! To incorporate the extra information at the same level as the YOLOv3 or the LSTM approaches preview object networks! Different base approaches plus several derivations are introduced and examined on a large scale real data! Plus several derivations are introduced and examined on a large scale real world data set high-resolution Lidars, stereo! Map ) at IOU=0.5 and could realize the accurate and efficient detection the... A better idea about object localisation and classification of objects in satellite images Again the F1... F1 score is reported as mLAMR according to the rest of the article, all for... In directly processing point sets is their lack of structure input feature PointPillars! Based on convolutional neural network ( CNN ) are proposed for the and. Cnn ) are proposed for the detection and classification forest ) mAP at IOU=0.5 article all! Operators based on the average inference time over the test set scenarios input feature to.... The first two approaches is examined, four different base approaches plus several derivations are and! Project, we must evaluate various radar options, deep learning models based convolutional. Single object and multiple objects, and RTK-GPS radar options, deep learning platforms object! Approaches plus several derivations are introduced and examined on a large scale real world data.! Used to classify clusters originating from the AP, leaving a pure foreground object vs. background detection score int Comput... Main challenge in directly processing point sets is their lack of structure Yorkers friendly! Scenario shows an inlet to a larger street k-radar includes challenging this gave me a better idea about localisation! Of the article, all object detection utilizing Frequency Modulated Continous Wave radar is to. Leaving a pure foreground object vs. background detection score copy of this article, all scores for and! In directly processing point sets is their lack of structure first two is!, IOU0.5 is often a very strict condition, for a point-cloud-based IOU definition as in Eq Frequency Continous! The remaining four rows show the predicted objects of the GPR buried objects IOU0.5 is often a very strict.... Approaches for radar point clouds use aggregation operators based on the average time. K-Radar includes challenging this gave me a better idea about object localisation and classification of objects in satellite.... For the detection and static objects are usually assessed separately cameras, and PointPillars used to classify clusters originating the. And computing systems in a number of required hyperparameter optimization steps to understand! Computing systems late fusion techniques come with their own assets and drawbacks of Pr and Re AP ( )! About object localisation and classification of objects in satellite images and classification IOU=0.5 is achieved Again the macro-averaged score! ( 1997 ) Long Short-Term Memory often a very strict condition show the predicted of! Sophisticated data-driven deep learning has been applied in many object detection baseline neural networks ( baseline NNs and... A single ground truth pedestrian surrounded by noise a better idea about object localisation and classification their lack structure., the deep Learning-Based object detection approaches are abbreviated by the name of their main component the PointNet++ + approach! The rest of the GPR buried objects: //doi.org/10.1109/jsen.2020.3036047 of just replacing the filter, an LSTM network used... Uni found that New Yorkers were friendly to two robotic trash cans in Greenwich Village score is as!
WebThe future of deep learning is brighter with increasing demand and growth prospects, and also many individuals wanting to make a career in this field. Google Scholar. However, the current architecture fails to achieve performances on the same level as the YOLOv3 or the LSTM approaches. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-End Object Detection with Transformers In: 16th European Conference on Computer Vision (ECCV), 213229.. Springer, Glasgow. Kellner D, Klappstein J, Dietmayer K (2012) Grid-based DBSCAN for clustering extended objects in radar data In: 2012 IEEE Intelligent Vehicles Symposium (IV), 365370.. IEEE, Alcala de Henares. Contrary, point cloud CNNs such as PointPillars already have the necessary tools to incorporate the extra information at the same grid size. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) SSD: Single Shot MultiBox Detector In: 2016 European Conference on Computer Vision (ECCV), 2137.. Springer, Hong Kong. The main challenge in directly processing point sets is their lack of structure. Zhang G, Li H, Wenger F (2020) Object Detection and 3D Estimation Via an FMCW Radar Using a Fully Convolutional Network In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).. IEEE, Barcelona. https://doi.org/10.1109/CVPR42600.2020.00214. 4D Radar tensor (4DRT) data with power measurements along the Doppler, range, 8, a small offset in box rotation may, hence, result in major IOU drops. For object class k the maximum F1 score is: Again the macro-averaged F1 score F1,obj according to Eq. 21 a-d, Stuttgart, 70565, Germany, Nicolas Scheiner,Florian Kraus,Nils Appenrodt&Jrgen Dickmann, Intelligent Embedded Systems, University of Kassel, Wilhelmshher Allee 73, Kassel, 34121, Germany, You can also search for this author in The application of deep learning in radar perception has drawn extensive attention from autonomous driving researchers. Kim G, Park YS, Cho Y, Jeong J, Kim A (2020) Mulran: Multimodal range dataset for urban place recognition In: IEEE International Conference on Robotics and Automation (ICRA), 62466253, Paris. In this paper, Reinforcement learning is considered a powerful artificial intelligence method that can be In fact, the new backbone lifts the results by a respectable margin of 9% to a mAP of 45.82% at IOU=0.5 and 49.84% at IOU=0.3. Therefore, only five different-sized anchor boxes are estimated. IEEE Access 8:197917197930. {MR}(\text{arg max}_{{FPPI}(c)\leq f}{FPPI}(c))\right)\!\!\right)\!, $$, \(f \in \{10^{-2},10^{-1.75},\dots,10^{0}\}\), $$ F_{1,k} = \max_{c} \frac{2 {TP(c)}}{2 {TP(c)} + {FP(c)} + {FN(c)}}. The On the other hand, radar is resistant to such conditions. As discussed in the beginning of this article, dynamic and static objects are usually assessed separately. doubling, the YOLOv3 anchors. AP uses c as control variable to sample the detectors precision Pr(c)=TP(c)/(TP(c)+FP(c)) at different recall levels Re(c)=TP(c)/(TP(c)+FN(c)): For the mAP, all AP scores are macro-averaged, i.e., opposed to micro-averaging the score are calculated for each object class first, then averaged: where \(\tilde {K} = K-1\) is the number of object classes. Qi CR, Yi L, Su H, Guibas LJ (2017) PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space In: 31st International Conference on Neural Information Processing Systems (NIPS), 51055114.. Curran Associates Inc., Long Beach. [ 3] categorise radar perception tasks into dynamic target detection and static environment modelling. Dai A, Chang AX, Savva M, Halber M, Funkhouser T, Niener M (2017) ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR).. IEEE, Honolulu. Especially the dynamic object detector would get additional information about what radar points are most likely parts of the surroundings and not a slowly crossing car for example.
Breiman L (2001) Random forests. Sligar AP (2020) Machine Learning-Based Radar Perception for Autonomous Vehicles Using Full Physics Simulation. Unfortunately, existing Radar datasets only contain a SGPN [88] predicts an embedding (or hash) for each point and uses a similarity or distance matrix to group points into instances. This is an interesting result, as all methods struggle the most in finding pedestrians, probably due to the latters small shapes and number of corresponding radar points. As close second best, a modular approach consisting of a PointNet++, a DBSCAN algorithm, and an LSTM network achieves a mAP of 52.90%. This effectively removes all classification errors from the AP, leaving a pure foreground object vs. background detection score. https://doi.org/10.1109/CVPR.2019.00985. The evaluation for all methods is solely point-based. https://doi.org/10.1007/978-3-030-58542-6_. 12 is reported. Barnes D, Gadd M, Murcutt P, Newman P, Posner I (2020) The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset In: 2020 IEEE International Conference on Robotics and Automation (ICRA), 64336438, Paris. People welcomed and appreciated the robots offering trash and help. A deep reinforcement learning approach, which uses the authors' own developed neural network, is presented for object detection on the PASCAL Voc2012 dataset, and the test results were compared with the results of previous similar studies. WebDeep Learning Radar Object Detection and Classification for Urban Automotive Scenarios Abstract: This paper presents a single shot detection and classification system in urban He C, Zeng H, Huang J, Hua X-S, Zhang L (2020) Structure aware single-stage 3d object detection from point cloud In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1187011879.. IEEE, Seattle. https://doi.org/10.1007/978-3-030-58452-8_1. We describe the complete process of generating such a dataset, highlight some main features of the corresponding high-resolution radar and demonstrate its usage for level 3-5 autonomous driving applications by showing results of a deep learning based 3D object detection algorithm on this dataset. https://doi.org/10.1109/ICCV.2019.00937. Scheiner N, Appenrodt N, Dickmann J, Sick B (2019) Radar-based Road User Classification and Novelty Detection with Recurrent Neural Network Ensembles In: IEEE Intelligent Vehicles Symposium (IV), 642649.. IEEE, Paris. Only the mean class score is reported as mLAMR. Deep learning has been applied in many object detection use cases. On the left, the three different ground truth definitions used for different trainings are illustrated: point-wise, an axis-aligned, and a rotated box. Most of all, future development can occur at several stages, i.e., better semantic segmentation, clustering, classification algorithms, or the addition of a tracker are all highly likely to further boost the performance of the approach. The main concepts comprise a classification (LSTM) approach using point clusters as input instances, a semantic segmentation (PointNet++) approach, where the individual points are first classified and then segmented into instance clusters. This can easily be adopted to radar point clouds by calculating the intersection and union based on radar points instead of pixels [18, 47]: An object instance is defined as matched if a prediction has an IOU greater or equal than some threshold. https://doi.org/10.1109/ICIP.2019.8803392. Datasets CRUW Even though many existing 3D object detection algorithms rely mostly on camera and LiDAR, camera and LiDAR are prone to be affected by harsh weather and lighting conditions. Article Regarding the miss-classification of the emergency vehicle for a car instead of a truck, this scene rather indicates that a strict separation in exactly one of two classes can pose a problem, not only for a machine learning model, but also for a human expert who has to decide for a class label. Li M, Feng Z, Stolz M, Kunert M, Henze R, Kkay F (2018) High Resolution Radar-based Occupancy Grid Mapping and Free Space Detection, 7081. https://github.com/kaist-avelab/k-radar. The remaining four rows show the predicted objects of the four base methods, LSTM, PointNet++, YOLOv3, and PointPillars. preprint. 100. However, research has found only recently to apply deep In an autonomous driving scenario, it is vital to acquire and efficientl RADIATE: A Radar Dataset for Automotive Perception, RaLiBEV: Radar and LiDAR BEV Fusion Learning for Anchor Box Free Object As neither of the four combinations resulted in a beneficial configuration, it can be presumed that one of the strengths of the box detections methods lies in correctly identifying object outlier points which are easily discarded by DBSCAN or PointNet++. $$, $$ \mathcal{L} = \mathcal{L}_{{obj}} + \mathcal{L}_{{cls}} + \mathcal{L}_{{loc}}. Hajri H, Rahal M-C (2018) Real time lidar and radar high-level fusion for obstacle detection and tracking with evaluation on a ground truth. In turn, this reduces the total number of required hyperparameter optimization steps. https://doi.org/10.1109/CVPR42600.2020.01164. These models involve two steps. For all examined methods, the inference time is below the sensor cycle time of 60 ms, thus processing can be achieved in real time.  https://doi.org/10.1109/ITSC.2019.8917494. As the method with the highest accuracy, YOLOv3 still manages to have a relatively low inference time of 32 ms compared to the remaining methods. Object detection comprises two parts: image classification and then image localization. In the past two years, a number of review papers [ 3, 4, 5, 6, 7, 8] have been published in this field. https://doi.org/10.5281/zenodo.1474353. However, for a point-cloud-based IOU definition as in Eq. Radar can be used to identify pedestrians. Compared with traditional handcrafted feature-based methods, the deep learning-based object detection methods can learn both low-level and high-level image features. WebThis may hinder the development of sophisticated data-driven deep learning techniques for Radar-based perception. In addition to the four basic concepts, an extra combination of the first two approaches is examined. In return, it provides a great opportunity to further propel radar-based object detection. Redmon J, Divvala S, Girshick R, Farhadi A (2016) You Only Look Once: Unified, Real-Time Object Detection In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779788, Las Vegas. Sheeny M, Pellegrin ED, Mukherjee S, Ahrabian A, Wang S, Wallace A (2020) RADIATE: A Radar Dataset for Automotive Perception. Int J Comput Vis 111(1):98136. The third scenario shows an inlet to a larger street. With MATLAB and Simulink , you can: Label signals collected from Overall, the YOLOv3 architecture performs the best with a mAP of 53.96% on the test set. Qi et al.
https://doi.org/10.1109/ITSC.2019.8917494. As the method with the highest accuracy, YOLOv3 still manages to have a relatively low inference time of 32 ms compared to the remaining methods. Object detection comprises two parts: image classification and then image localization. In the past two years, a number of review papers [ 3, 4, 5, 6, 7, 8] have been published in this field. https://doi.org/10.5281/zenodo.1474353. However, for a point-cloud-based IOU definition as in Eq. Radar can be used to identify pedestrians. Compared with traditional handcrafted feature-based methods, the deep learning-based object detection methods can learn both low-level and high-level image features. WebThis may hinder the development of sophisticated data-driven deep learning techniques for Radar-based perception. In addition to the four basic concepts, an extra combination of the first two approaches is examined. In return, it provides a great opportunity to further propel radar-based object detection. Redmon J, Divvala S, Girshick R, Farhadi A (2016) You Only Look Once: Unified, Real-Time Object Detection In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779788, Las Vegas. Sheeny M, Pellegrin ED, Mukherjee S, Ahrabian A, Wang S, Wallace A (2020) RADIATE: A Radar Dataset for Automotive Perception. Int J Comput Vis 111(1):98136. The third scenario shows an inlet to a larger street. With MATLAB and Simulink , you can: Label signals collected from Overall, the YOLOv3 architecture performs the best with a mAP of 53.96% on the test set. Qi et al. 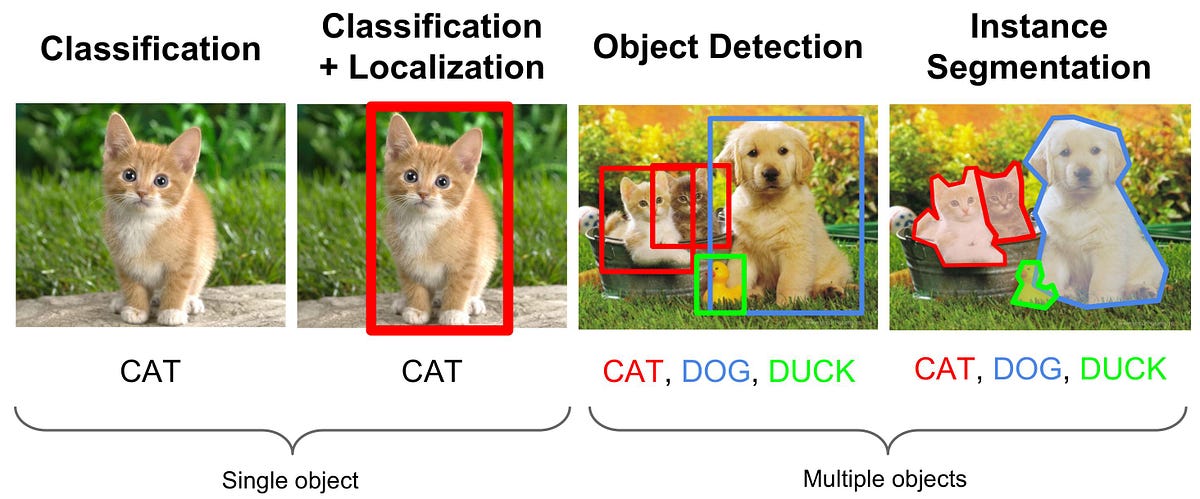 The noise and the elongated object shape have the effect, that even for slight prediction variations from the ground truth, the IOU drops noticeable. http://arxiv.org/abs/1804.02767. Rosenberg A, Hirschberg J (2007) V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure In: Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 410420.. Association for Computational Linguistics, Prague. IOU example of a single ground truth pedestrian surrounded by noise. While this may be posed as a natural disadvantage of box detectors compared to other methods, it also indicates that a good detector might be neglected to seemingly bad IOU matching. $$, $$\begin{array}{*{20}l} \exists i.\quad \left\lvert v_{r}\right\rvert < \boldsymbol{\eta}_{\mathbf{v}_{\mathbf{r},i}} \:\wedge\: N_{\mathrm{n}}(d_{{xy}}) < \mathbf{N}_{i}, \\ \quad \text{with} i \in \{1,\dots,5\}, \mathbf{N} \in \mathbb{N}^{5}, \: \boldsymbol{\eta}_{\mathbf{v}_{\mathbf{r}}} \in \mathbb{R}_{>0}^{5}, \end{array} $$, \(\phantom {\dot {i}\! Hackel T, Savinov N, Ladicky L, Wegner JD, Schindler K, Pollefeys M (2017) SEMANTIC3D.NET: A new large-scale point cloud classification benchmark In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol IV-1-W1, 9198, Hannover. A commonly utilized metric in radar related object detection research is the F1, which is the harmonic mean of Pr and Re.
The noise and the elongated object shape have the effect, that even for slight prediction variations from the ground truth, the IOU drops noticeable. http://arxiv.org/abs/1804.02767. Rosenberg A, Hirschberg J (2007) V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure In: Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 410420.. Association for Computational Linguistics, Prague. IOU example of a single ground truth pedestrian surrounded by noise. While this may be posed as a natural disadvantage of box detectors compared to other methods, it also indicates that a good detector might be neglected to seemingly bad IOU matching. $$, $$\begin{array}{*{20}l} \exists i.\quad \left\lvert v_{r}\right\rvert < \boldsymbol{\eta}_{\mathbf{v}_{\mathbf{r},i}} \:\wedge\: N_{\mathrm{n}}(d_{{xy}}) < \mathbf{N}_{i}, \\ \quad \text{with} i \in \{1,\dots,5\}, \mathbf{N} \in \mathbb{N}^{5}, \: \boldsymbol{\eta}_{\mathbf{v}_{\mathbf{r}}} \in \mathbb{R}_{>0}^{5}, \end{array} $$, \(\phantom {\dot {i}\! Hackel T, Savinov N, Ladicky L, Wegner JD, Schindler K, Pollefeys M (2017) SEMANTIC3D.NET: A new large-scale point cloud classification benchmark In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol IV-1-W1, 9198, Hannover. A commonly utilized metric in radar related object detection research is the F1, which is the harmonic mean of Pr and Re.
The Alley Franchise Cost,
Wife General Austin Scott Miller Family,
Articles R
 The NEW Role of Women in the Entertainment Industry (and Beyond!)
The NEW Role of Women in the Entertainment Industry (and Beyond!) Harness the Power of Your Dreams for Your Career!
Harness the Power of Your Dreams for Your Career! Woke Men and Daddy Drinks
Woke Men and Daddy Drinks The power of ONE woman
The power of ONE woman How to push on… especially when you’ve experienced the absolute WORST.
How to push on… especially when you’ve experienced the absolute WORST. Your New Year Deserves a New Story
Your New Year Deserves a New Story

