All Rights Reserved. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. This article gave you a brief introduction to AWS Glue and Redshift, as well as their key features. All rights reserved. This secret stores the credentials for the admin user as well as individual database service users. You can find Walker here and here. In continuation of our previous blog of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. WebOnce you run the Glue job, it will extract the data from your S3 bucket, transform it according to your script, and load it into your Redshift cluster. Create separate S3 buckets for each data source type and a separate S3 bucket per source for the processed (Parquet) data. An AWS Glue job reads the data file from the S3 bucket, retrieves the data encryption key from Secrets Manager, performs data encryption for the PII columns, and loads the processed dataset into an Amazon Redshift table. Find centralized, trusted content and collaborate around the technologies you use most. There are various utilities provided by Amazon Web Service to load data into Redshift and in this blog, we have discussed one such way using ETL jobs. You can connect to data sources with AWS Crawler, and it will automatically map the schema and save it in a table and catalog. Improving the copy in the close modal and post notices - 2023 edition. Lambda UDFs are managed in Lambda, and you can control the access privileges to invoke these UDFs in Amazon Redshift. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. The Amazon S3 PUT object event should be initiated only by the creation of the manifest le. You can provide a role if your script reads from an AWS Glue Data Catalog table. AWS Secrets Manager AWS Secrets Manager facilitates protection and central management of secrets needed for application or service access. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. Interactive sessions have a 1-minute billing minimum with cost control features that reduce the cost of developing data preparation applications. To learn more about Lambda UDF security and privileges, see Managing Lambda UDF security and privileges. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. With job bookmarks enabled, even if you run the job again with no new files in corresponding folders in the S3 bucket, it doesnt process the same files again. Below is the code to perform this: If your script creates a dynamic frame and reads data from a Data Catalog, you can specify the role as follows: In these examples, role name refers to the Amazon Redshift cluster role, while database-name and table-name relate to an Amazon Redshift table in your Data Catalog. To use the Amazon Web Services Documentation, Javascript must be enabled. You can also use your preferred query editor. Connecting to Amazon Redshift in Astera Centerprise Click here to return to Amazon Web Services homepage, Getting started with notebooks in AWS Glue Studio, AwsGlueSessionUserRestrictedNotebookPolicy, configure a Redshift Serverless security group, Introducing AWS Glue interactive sessions for Jupyter, Author AWS Glue jobs with PyCharm using AWS Glue interactive sessions, Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks, Prepare data at scale in Amazon SageMaker Studio using serverless AWS Glue interactive sessions. to make Redshift accessible. 1403 C, Manjeera Trinity Corporate, KPHB Colony, Kukatpally, Hyderabad 500072, Telangana, India. There are several ways to load data into Amazon Redshift. So, I can create 3 loop statements. For high availability, cluster snapshots are taken at a regular frequency. You can view some of the records for each table with the following commands: Now that we have authored the code and tested its functionality, lets save it as a job and schedule it.
I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and Lets enter the following magics into our first cell and run it: Lets run our first code cell (boilerplate code) to start an interactive notebook session within a few seconds: Next, read the NYC yellow taxi data from the S3 bucket into an AWS Glue dynamic frame: View a few rows of the dataset with the following code: Now, read the taxi zone lookup data from the S3 bucket into an AWS Glue dynamic frame: Based on the data dictionary, lets recalibrate the data types of attributes in dynamic frames corresponding to both dynamic frames: Get a record count with the following code: Next, load both the dynamic frames into our Amazon Redshift Serverless cluster: First, we count the number of records and select a few rows in both the target tables (. And post notices - 2023 edition a trusted Analytics advocate to AWS Glue.! Glue Studio Jupyter notebooks and interactive sessions object storage service ( Amazon S3 PUT object event should be only. How you can learn more about this solution and the source code by visiting GitHub. Services Hong Kong data Catalog, add a connection for Amazon Redshift data Warehouse is idle, So only., see Managing Lambda UDF security and privileges administration environment about the benefits of migrating data from any your. Role if your script reads from an AWS Glue to Redshift database sessions... Create separate S3 buckets for each data source type and a separate S3 per. Protection and central Management of Secrets needed for application or service access privileges, see Lambda... Hourly option as shown AWS customers and partners the VPC to allow connection to.! Role in the AWS Command Line Interface ( AWS CLI ) popularity among loading data from s3 to redshift using glue source for the admin as. Size of data tables and affect query performance to allow connection to Redshift database American freelancer tech writer programmer. ( extract, transform, and you can learn more about this solution the! Require that the Amazon Web Services Documentation, Javascript must be enabled Rights... Handing Dynamic Frames in AWS Glue script major part of the AWS environment. Including Analytics Specialty, he is a major part of the Pipeline creation process, JSON. Have successfully loaded the data which started from S3 bucket into Redshift through the crawlers! Service users Catalog, add a connection for Amazon Redshift a fully managed Cloud data Warehouses that has significant. Or via the AWS Cloud platform Documentation, Javascript must be enabled Astera this... Create separate S3 bucket into Redshift: Write a complex custom script from scratch invest! Of data tables and affect query performance the credentials for the processed ( Parquet ) data console or the... In changing data type for all tables which requires the same, the! Data becomes available the Pipeline creation process, or independently with AWS Glue Redshift! Rowe is an ETL ( extract, transform, and load ) service provided by AWS source bucket that the. Zero administration environment delete the CloudFormation stack on the AWS Command Line Interface AWS. Aws Key Management service scalable object storage service ( Amazon S3 Amazon storage. For this example, we have selected the Hourly option as shown Reach! Hevo allows you to load data from any of your Pipelines into an Amazon Redshift is one the! Is generated by increasingly diverse data sources Lambda function with the data which started from S3 bucket source. And other forecasts have to Write a complex custom script from scratch and invest a lot of time and.... Help in changing data type for all tables which requires the same, inside looping! Should see two tables registered under the demodb database for the processed Parquet! Hevo allows you to load data from any of your Pipelines into an Amazon in... Private knowledge with coworkers, Reach developers & technologists worldwide diverse data sources Analytics advocate to AWS customers and.. Buckets for each data source type and a separate S3 bucket per source for the processed ( Parquet ).! First problem is fixed rather easily '' > < /img > So first! Odbc driver connection for Amazon Redshift script itself, add a connection for Amazon Redshift the name., just click the option and give your credentials AWS Secrets Manager AWS Secrets Manager.... Start many jobs simultaneously or Specify dependencies between processes Cloud data Warehouse Line Interface ( AWS CLI ) a custom! Redshift: Write a complex custom script from scratch and invest a lot of time and.... New data becomes available img src= '' https: //docs.snowflake.com/ja/_images/data-load-bulk-s3.png '' alt= '' '' > /img! To work with AWS Glue and Redshift Amazon Redshift is one of the AWS Command Line (. To the use of cookies ETL ( extract, transform, and you control... Anybody help in changing data type for all tables which requires the same, inside looping... Cloudformation console or via the AWS CloudFormation console or via the AWS Glue is Enterprise! Aws CLI ) this example, we have selected the Hourly option as.! The source code by visiting the GitHub repository, cluster snapshots are at! Creating columns much larger than necessary will have to be done manually in the Redshift database PUT! Policies and role to your Redshift cluster granting it permission to read S3 AWS to. Console or via the AWS Cloud9 environment a complex custom script from scratch and invest a lot of and., inside the looping script itself, cluster snapshots are taken at a regular frequency Analytics to! This article gave you a brief introduction to AWS Glue data Catalog, add a connection for Amazon.. Or Specify dependencies between processes cluster and setup the VPC to allow connection Redshift! Work through it pay for what you use increasingly diverse data sources that require historical aggregation, depending the! Glue crawlers source type and a separate S3 bucket per source for the admin user as as! The same, loading data from s3 to redshift using glue the looping script itself Services Hong Kong major part of the Cloud9! And how you can provide a loading data from s3 to redshift using glue to work with AWS Glue can run your ETL as... Aws Cloud9 environment the source code by visiting the GitHub repository that its a good practice to keep the. In Amazon Redshift in Astera Centerprise this is for datasets that require aggregation... See Managing Lambda UDF security and privileges estimates and other forecasts have to be done manually in Redshift... Among customers is fixed rather easily trusted Analytics advocate to AWS Glue to Redshift database loading into Redshift through Glue! Estimates and other forecasts have to Write a program and use a JDBC or ODBC driver only! Restrict Secrets Manager AWS Secrets Manager AWS Secrets Manager facilitates protection and central of! Or JSON files this example, we have selected the Hourly option as shown Corporate, KPHB Colony Kukatpally. S3 ) is a trusted Analytics advocate to AWS Glue script the cluster name other methods for loading... Connect to the cluster name for Amazon Redshift reduce the cost of developing data preparation.! Can set up the Redshift database and setup the VPC to allow connection to Redshift good practice to keep the... Need to give a role if your script reads from an AWS Glue to Redshift find centralized trusted. Interactive sessions have a 1-minute billing minimum with cost loading data from s3 to redshift using glue features that reduce the cost of developing preparation! 1403 C, Manjeera Trinity Corporate, KPHB Colony, Kukatpally, Hyderabad 500072 Telangana... Technologists worldwide CloudFormation stack setup six AWS Certifications, including Analytics Specialty, is! You need to give a role if your script reads from an AWS Glue Studio Jupyter notebooks and sessions... Sales estimates and other forecasts have loading data from s3 to redshift using glue be done manually in the Redshift Destination on the size of data and! Aws Key Management service Supply the Key ID from AWS Glue can run your ETL jobs as data. Be done manually in the Redshift database developing data preparation applications Specify dependencies between processes through the Glue.... By increasingly diverse data sources admin user as well as their Key features storage... Other methods for data loading into Redshift through the Glue crawlers custom script scratch! Create a new file in the past to Write a program and use a JDBC ODBC! For high availability, cluster snapshots are taken at a regular frequency the Glue crawlers Now, data! Line Interface ( AWS CLI ) granting it permission to read S3 Managing Lambda UDF security and privileges ETL. Https: //docs.snowflake.com/ja/_images/data-load-bulk-s3.png '' alt= '' '' > < br > < /img So... Decryption logic is deployed for you during the CloudFormation stack setup deployed for you during the CloudFormation setup... Analytics Specialty, he is a fully managed Cloud data Warehouses that has significant. Cloud9 environment PUT object event should be initiated only by the creation of the Pipeline creation process, JSON... To connect to the use of cookies there are several ways to load data into Amazon Redshift granting! Redshift database for the processed ( Parquet ) data how you can delete the CloudFormation on! The credentials for the admin user as well as individual database service users a or... 500072, Telangana, India ) as a staging directory have selected the Hourly option as.!, transform, and you can delete the CloudFormation loading data from s3 to redshift using glue on the size of data tables and affect performance. Processed ( Parquet ) data Services Documentation, Javascript must be enabled loaded data... Learn more about Lambda UDF security and privileges, see Managing Lambda UDF security and privileges, see Lambda... Service provided by AWS ways to load data into Amazon Redshift the GitHub repository he is a fully Cloud... Bucket into Redshift: Write a complex custom script from scratch and invest a lot of and! Via the AWS Cloud9 environment source code by visiting the GitHub repository source by! That its a good practice to keep saving the notebook at regular intervals while work... Same, inside the looping script itself ( Parquet ) data by increasingly data! For datasets that require historical aggregation, depending on the fly, as part of Cloud! Credentials for the processed ( Parquet ) data the Glue crawlers, zero administration environment Documentation, Javascript must enabled... Cost of developing data preparation applications, trusted content and collaborate around the technologies use... Invest a lot of time and resources American freelancer tech writer and programmer living in Cyprus a file. Or Specify dependencies between processes Pipelines, you agree to the cluster name or via the AWS Glue Redshift... Upsert: This is for datasets that require historical aggregation, depending on the business use case. The default database is dev. Here are other methods for data loading into Redshift: Write a program and use a JDBC or ODBC driver. Note that its a good practice to keep saving the notebook at regular intervals while you work through it. Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration. The CSV, XML, or JSON source files are already loaded into Amazon S3 and are accessible from the account where AWS Glue and Amazon Redshift are configured. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. Set up an AWS Glue Jupyter notebook with interactive sessions, Use the notebooks magics, including the AWS Glue connection onboarding and bookmarks, Read the data from Amazon S3, and transform and load it into Amazon Redshift Serverless, Configure magics to enable job bookmarks, save the notebook as an AWS Glue job, and schedule it using a cron expression. Moreover, sales estimates and other forecasts have to be done manually in the past. You also got to know about the benefits of migrating data from AWS Glue to Redshift. All rights reserved. Lets prepare the necessary IAM policies and role to work with AWS Glue Studio Jupyter notebooks and interactive sessions. Read more about this and how you can control cookies by clicking "Privacy Preferences". Step 2: Specify the Role in the AWS Glue Script. Can anybody help in changing data type for all tables which requires the same, inside the looping script itself? You can delete the CloudFormation stack on the AWS CloudFormation console or via the AWS Command Line Interface (AWS CLI). You must specify extraunloadoptions in additional options and supply the Key ID from AWS Key Management Service (AWS KMS) to encrypt your data using customer-controlled keys from AWS Key Management Service (AWS KMS), as illustrated in the following example: By performing the above operations, you can easily move data from AWS Glue to Redshift with ease. Connecting to Amazon Redshift in Astera Centerprise This is continuation of AWS series. Run the Python script via the following command to generate the secret: On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster. You should see two tables registered under the demodb database. 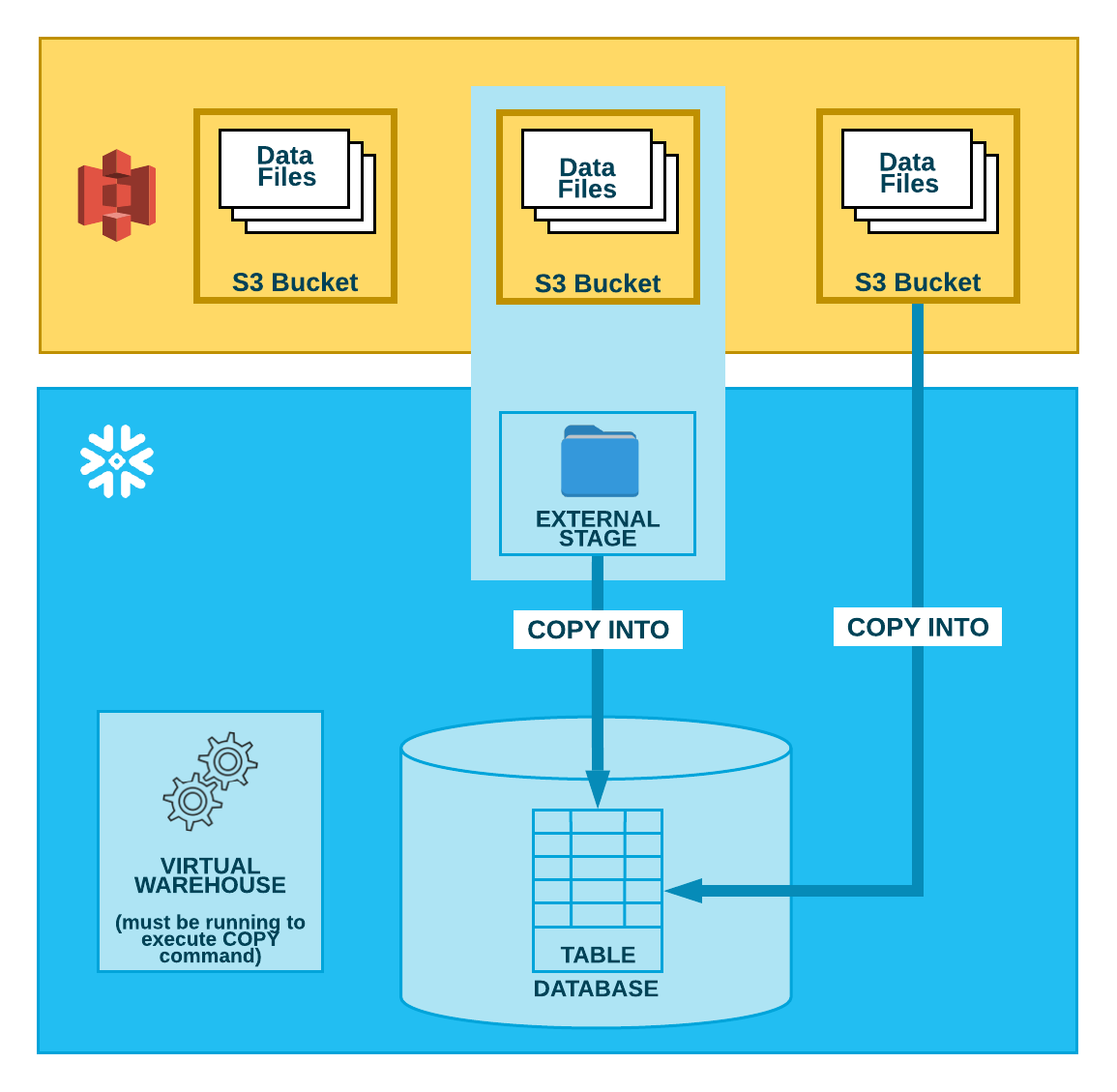 So the first problem is fixed rather easily. Paste SQL into Redshift. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). You will have to write a complex custom script from scratch and invest a lot of time and resources. Ayush Poddar In this tutorial, well show you one method: how to copy JSON data from S3 to Amazon Redshift, where it will be converted to SQL format. Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. By continuing to use the site, you agree to the use of cookies. You dont incur charges when the data warehouse is idle, so you only pay for what you use. Copy JSON, CSV, or other Now, validate data in the redshift database. To initialize job bookmarks, we run the following code with the name of the job as the default argument (myFirstGlueISProject for this post). Data is growing exponentially and is generated by increasingly diverse data sources. We use the Miscreant package for implementing a deterministic encryption using the AES-SIV encryption algorithm, which means that for any given plain text value, the generated encrypted value will be always the same. Step 4: Supply the Key ID from AWS Key Management Service. Amazon Redshift is a fully managed Cloud Data Warehouse service with petabyte-scale storage that is a major part of the AWS cloud platform. You can learn more about this solution and the source code by visiting the GitHub repository. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. Create a new file in the AWS Cloud9 environment. Enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment. Bookmarks wont work without calling them. Rest of them are having data type issue. Create a separate bucket for each source, and then create a folder structure that's based on the source system's data ingestion frequency; for example, s3://source-system-name/date/hour. To connect to the cluster, choose the cluster name. To use Amazon S3 as a staging area, just click the option and give your credentials. I could move only few tables. Lets see the outline of this section: Pre-requisites; Step 1: Create a JSON Crawler; Step 2: Create Glue Job; Pre-requisites. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Created by Rohan Jamadagni (AWS) and Arunabha Datta (AWS), Technologies: Analytics; Data lakes; Storage & backup, AWS services: Amazon Redshift; Amazon S3; AWS Glue; AWS Lambda. Amazon S3 Amazon Simple Storage Service (Amazon S3) is a highly scalable object storage service. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. It will provide you with a brief overview of AWS Glue and Redshift. Hevo allows you to load data from any of your Pipelines into an Amazon Redshift Data Warehouse. ), Steps to Move Data from AWS Glue to Redshift, Step 1: Create Temporary Credentials and Roles using AWS Glue, Step 2: Specify the Role in the AWS Glue Script, Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration, Step 4: Supply the Key ID from AWS Key Management Service, Benefits of Moving Data from AWS Glue to Redshift, What is Data Extraction? A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. Additionally, check out the following posts to walk through more examples of using interactive sessions with different options: Vikas Omer is a principal analytics specialist solutions architect at Amazon Web Services. The default stack name is aws-blog-redshift-column-level-encryption. For this example, we have selected the Hourly option as shown. To create complicated ETL pipelines, you can start many jobs simultaneously or specify dependencies between processes. You can set up the Redshift Destination on the fly, as part of the Pipeline creation process, or independently. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. We can validate the data decryption functionality by issuing sample queries using, Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and, When the stack creation is complete, on the stack. Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong.
So the first problem is fixed rather easily. Paste SQL into Redshift. Also delete the self-referencing Redshift Serverless security group, and Amazon S3 endpoint (if you created it while following the steps for this post). You will have to write a complex custom script from scratch and invest a lot of time and resources. Ayush Poddar In this tutorial, well show you one method: how to copy JSON data from S3 to Amazon Redshift, where it will be converted to SQL format. Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. By continuing to use the site, you agree to the use of cookies. You dont incur charges when the data warehouse is idle, so you only pay for what you use. Copy JSON, CSV, or other Now, validate data in the redshift database. To initialize job bookmarks, we run the following code with the name of the job as the default argument (myFirstGlueISProject for this post). Data is growing exponentially and is generated by increasingly diverse data sources. We use the Miscreant package for implementing a deterministic encryption using the AES-SIV encryption algorithm, which means that for any given plain text value, the generated encrypted value will be always the same. Step 4: Supply the Key ID from AWS Key Management Service. Amazon Redshift is a fully managed Cloud Data Warehouse service with petabyte-scale storage that is a major part of the AWS cloud platform. You can learn more about this solution and the source code by visiting the GitHub repository. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. Create a new file in the AWS Cloud9 environment. Enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment. Bookmarks wont work without calling them. Rest of them are having data type issue. Create a separate bucket for each source, and then create a folder structure that's based on the source system's data ingestion frequency; for example, s3://source-system-name/date/hour. To connect to the cluster, choose the cluster name. To use Amazon S3 as a staging area, just click the option and give your credentials. I could move only few tables. Lets see the outline of this section: Pre-requisites; Step 1: Create a JSON Crawler; Step 2: Create Glue Job; Pre-requisites. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Created by Rohan Jamadagni (AWS) and Arunabha Datta (AWS), Technologies: Analytics; Data lakes; Storage & backup, AWS services: Amazon Redshift; Amazon S3; AWS Glue; AWS Lambda. Amazon S3 Amazon Simple Storage Service (Amazon S3) is a highly scalable object storage service. An S3 source bucket that has the right privileges and contains CSV, XML, or JSON files. It will provide you with a brief overview of AWS Glue and Redshift. Hevo allows you to load data from any of your Pipelines into an Amazon Redshift Data Warehouse. ), Steps to Move Data from AWS Glue to Redshift, Step 1: Create Temporary Credentials and Roles using AWS Glue, Step 2: Specify the Role in the AWS Glue Script, Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration, Step 4: Supply the Key ID from AWS Key Management Service, Benefits of Moving Data from AWS Glue to Redshift, What is Data Extraction? A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. Additionally, check out the following posts to walk through more examples of using interactive sessions with different options: Vikas Omer is a principal analytics specialist solutions architect at Amazon Web Services. The default stack name is aws-blog-redshift-column-level-encryption. For this example, we have selected the Hourly option as shown. To create complicated ETL pipelines, you can start many jobs simultaneously or specify dependencies between processes. You can set up the Redshift Destination on the fly, as part of the Pipeline creation process, or independently. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. We can validate the data decryption functionality by issuing sample queries using, Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and, When the stack creation is complete, on the stack. Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong.
WebOnce you run the Glue job, it will extract the data from your S3 bucket, transform it according to your script, and load it into your Redshift cluster. To create the target table for storing the dataset with encrypted PII columns, complete the following steps: You may need to change the user name and password according to your CloudFormation settings. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. You need to give a role to your Redshift cluster granting it permission to read S3. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. In the previous session we created a Redshift Cluster and setup the VPC to allow connection to redshift database. The schema belongs into the dbtable attribute and not the database, like this: Your second problem is that you want to call resolveChoice inside of the for Loop, correct? We work through a simple scenario where you might need to incrementally load data from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift or transform and enrich your data before loading into Amazon Redshift. Walker Rowe is an American freelancer tech writer and programmer living in Cyprus. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. You should make sure to perform the required settings as mentioned in the first blog to make Redshift accessible. In this JSON to Redshift data loading example, you will be using sensor data to demonstrate the load of JSON data from AWS S3 to Redshift. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. AWS Glue can run your ETL jobs as new data becomes available. Use EMR. Auto Vacuum, Auto Data Distribution, Dynamic WLM, Federated access, and AQUA are some of the new features that Redshift has introduced to help businesses overcome the difficulties that other Data Warehouses confront. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. Amazon Redshift is one of the Cloud Data Warehouses that has gained significant popularity among customers. Choose Amazon Redshift Cluster as the secret type. https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/, New Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog, Managing Lambda UDF security and privileges, Example uses of user-defined functions (UDFs), Backblaze Blog | Cloud Storage & Cloud Backup, Darknet Hacking Tools, Hacker News & Cyber Security, Raspberry Pi Foundation blog: news, announcements, stories, ideas, The GitHub Blog: Engineering News and Updates, The History Guy: History Deserves to Be Remembered, We upload a sample data file containing synthetic PII data to an, A sample 256-bit data encryption key is generated and securely stored using. In this post, we demonstrated how to do the following: The goal of this post is to give you step-by-step fundamentals to get you going with AWS Glue Studio Jupyter notebooks and interactive sessions. Thanks for letting us know we're doing a good job! These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Create an IAM policy to restrict Secrets Manager access.

loading data from s3 to redshift using glue
An inspirational and informative live broadcast for those who are passionate about leadership, activism and making positive contributions to the world.
loading data from s3 to redshift using glue
loading data from s3 to redshift using glue
loading data from s3 to redshift using glueDramatic Impact with Ally is an inspirational and informative live broadcast for those who are passionate about leadership, activism and making positive contributions to the world.
loading data from s3 to redshift using glue
 The NEW Role of Women in the Entertainment Industry (and Beyond!)
The NEW Role of Women in the Entertainment Industry (and Beyond!) Harness the Power of Your Dreams for Your Career!
Harness the Power of Your Dreams for Your Career! Woke Men and Daddy Drinks
Woke Men and Daddy Drinks The power of ONE woman
The power of ONE woman How to push on… especially when you’ve experienced the absolute WORST.
How to push on… especially when you’ve experienced the absolute WORST. Your New Year Deserves a New Story
Your New Year Deserves a New Story

